


Ever heard the phrase, "we eat our own dog food?" We eat what we serve here at PDQ.com. We have been 100% remote since mid March. We were not expecting to go remote so quickly. PDQ.com made the decision to go remote at around 1:00 PM on a Thursday and had everyone out the door with equipment by 5:00 PM. That's it, hardware issued and we're done, right? I wish it were just that easy. The IT team, myself included, thought we had just claimed a monumental victory. The reality of the situation didn't set in until the following Monday.
Just as a precursor to this, you will want to familiarize yourself with how PDQ Deploy and PDQ Inventory work. Here are a couple of fun reads:
The TL;DR for the 75% of you that will ignore the two links above: PDQ needs to be able to accurately resolve target computer names to IP addresses needs to be able to ping the target and needs to be able to communicate with the target over SMB bidirectionally.
The problem space
The first thing we noticed Monday morning was we could only have 15 people connected to the VPN at a time; this was not an issue previously as there was never more than that many people connecting. After about 15 minutes of scratching our heads and digging through logs, it hit us; we had only allocated 15 IP addresses in the DHCP scope that our firewall was in control of. A quick configuration change, and then the flood gates opened. In a matter of moments, we saw the increased load on the firewall. A typical workload for our firewall was 4-5 simultaneous VPN users at any given time, overnight the new normal was 45-50 simultaneous VPN users.
With the significant load increase on our edge devices, we had to change our patching and scanning strategies quickly. When we were (mostly) all at the office, we were pushing updates to our internal machines almost immediately after the packaging team made the updates public. Using a single Microsoft OS cumulative update as an example with around 100 devices targeted, that translated to nearly 200 GB of transfer. In the office where the slowest trunk is 10Gb, 200GB is laughable. Now that we are on an SD-WAN of 2Gb/s 200GB for a single CU along with all of the other traffic 200GB is the orange, we are trying to squeeze through a garden hose. That is when Deploy isn't throwing a temper tantrum about not being able to find our targets in DNS.
DNS. It's always DNS isn't it? Even when it's not, it is. On our support team, it's sort of an inside joke that when we are stumped, someone inevitably has to say, "have you verified DNS is behaving?" even if the issue is nowhere near related on the surface. You'd be surprised how many times DNS plays a role in the resolution of those tickets. This was our first major hurdle. Sure we can deploy to IP addresses that we can pull from the firewall, but that is a ton of manual work. At this point, it's probably best to describe the ideal scenario. For those of you that fall into this boat congrats. For the rest of us, take another drink.
The solution(s)
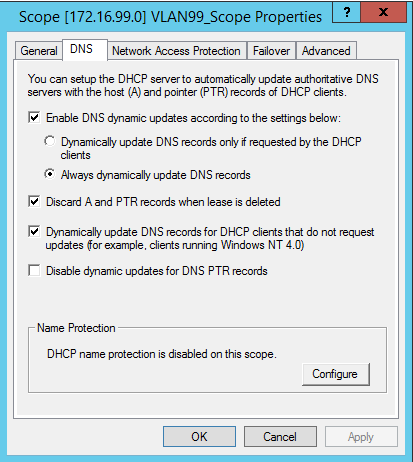
My first plan of attack was to use a DHCP relay. If I could get our Microsoft DHCP server issuing leases to VPN Connected clients, I could control DNS updates in that fashion. Ideally, I would have created a new scope for this and set the lease times exceptionally short, 10 hours maximum. Then I would configure the DHCP server to modify DNS records as leases are issued and deleted. I would suggest configuring this in most environments VPN connected clients or otherwise.
Thinking this through with user Billy as an example:
8:00 AM Billy connects to the VPN, gets a lease of 10.10.10.50, and the DHCP server registers LT-BILLY to DNS.
12:30 PM Billy disconnects from the VPN to get lunch then reconnects. Billy gets the same IP because the lease is still active.
5:00 PM Billy disconnects from the VPN and goes to answer the same question we've all been asking ourselves during this time, am I hungry or bored? Billy is done working for the night.
6:00 PM The lease of 10.0.10.10.50 expires since LT-BILLY is not around to renew. The DHCP server then removes the A and PTR records created at 8:00 AM that morning.
DNS stays updated, Deploy and Inventory keep chugging away. It's like Billy never left the office, except things are slightly slower.
The reality
Unfortunately, this isn't the reality for us; we were not able to use a DHCP relay and still make use of split tunneling. Split tunneling was a hard requirement for us. Here is what we did to keep things working for us.
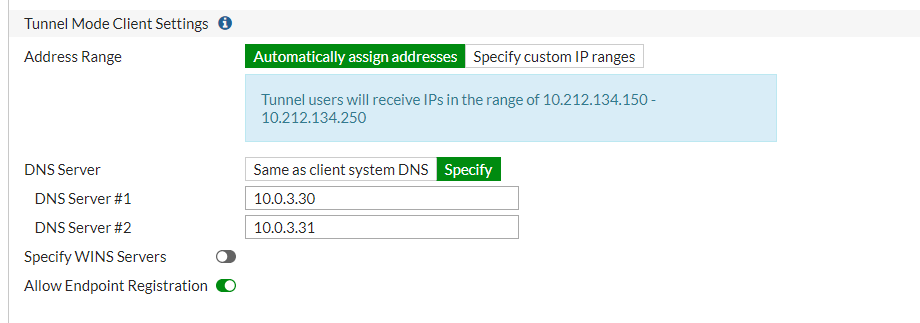
First, we needed to make sure that, at a minimum, our clients were able to register in DNS. In our firewall, we were able to define the DNS servers issued to connected clients. When they had to specifically allow them to register in DNS. The default behavior was to issue the same DNS servers the firewall was using for its internal interface and not allow endpoint registration.
At this point, we had devices registering in DNS though it was a mess. Every time a user would disconnect and reconnect, they got a new IP address and, therefore a new DNS entry. Our firewall’s concept of DHCP seems to be session-based, not time-based. A glance at our DNS zone showed 5-6 ‘A’ records for every laptop that connected. As you can imagine, Inventory’s scan status column showed nothing but “DNS Mismatch.” The other thing we noticed is that by enabling the clients to register in DNS, ALL of the adapters installed on the system with an active IP were registered to internal zones. If you look at my machine in the screenshot below “LT-JOSH02-DEV”, you’ll see that I have registered my home network 172.16.0.0/24 as well as two VMware workstation adapters on the system 192.168.88.0/24 and 192.168.29.0/24.
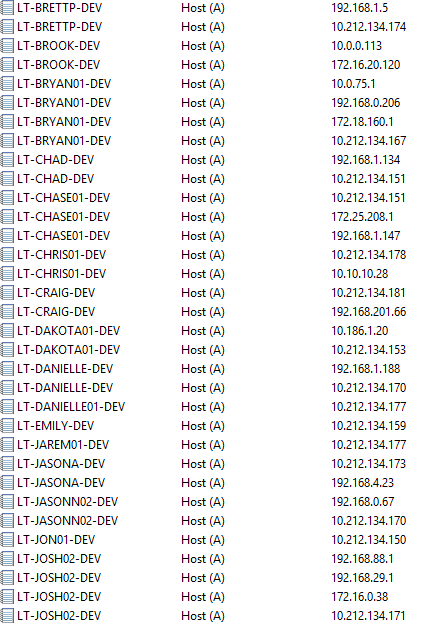
Keep in mind that this is our cleaned up zone. Prior to this, LT-JOSH02-DEV could have easily been entered this many times as I connected and disconnected from the VPN in rapid succession.
We were able to achieve this somewhat clean zone by a combination of scavenging and communication to the worst offenders (people connecting and disconnecting many times throughout the day) For all the information on scavenging you’d ever want and more check out Brigg gets way too excited about DNS here:
We ended up setting our scavenging to the following:
No-refresh interval 5 hours
Refresh interval of 5 hours
Scavenging period of 3 hours
This would mean that anywhere between 10 hours and 1 second and 12 hours 59 minutes and 59 seconds, a DNS record that did not get updated would be purged. This is highly aggressive scavenging. Keep in mind that by default, Windows machines do not update their registration this often. If you enable these settings alone without additional configuration, you are going to have a bad time. The only way we were able to get away with these aggressive settings is because we have our DHCP server updating DNS records for the machines that are still in the office, and our VPN client is registering DNS clients each time they connect to the network.
At this point we’ve got machines getting routable IP addresses, those addresses are registering in DNS (along with some of their friends), and SMB traffic is flowing bidirectionally. Now, all we need to do is make some tweaks to PDQ Deploy and PDQ Inventory, and we’ll be well on our way to the next.
PDQ-specific changes
The first thing we’ve got to do is somehow mitigate these multiple A records in DNS. PDQ Deploy and Inventory both have a setting to help account for this.
For Deploy: Preferences > Deployments > Ping before deployment
For Inventory: Preferences > Scanning > Ping before scanning
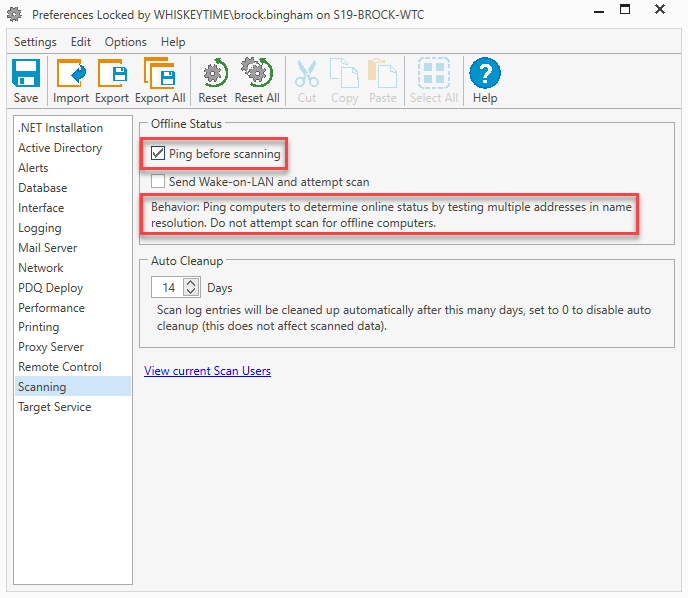
When this setting is enabled and PDQ attempts to resolve a target, a list of IP addresses (all of them that exist in DNS) will be returned. At this point, PDQ will start to try and establish SMB communication with the target. The first address that responds will be the address used. This setting does add a little bit of overhead as there may be multiple attempts to invalid IP addresses before a successful connection is made.
This setting also pings computers to determine their online status. In our experience, we were getting quite a few false positives when we were pinging before scanning. We have since attributed that to higher latency and some packet loss. We most often saw this when deploying to remote targets that were connected to slow or unreliable internet. PDQ only sends 2 ICMP echo requests to the target. If they are not returned in time or both timeout, the machine will be considered offline.
While we are in preferences, it's probably a good time to make some performance tweaks while dealing with machines over the VPN. This is going to take some trial and error on your part. We found with our configuration that "push" was faster for VPN connected clients and 20 concurrent deployments were the upper limit. Since we run a dedicated PDQ instance, we let this VM use 100% of its available bandwidth.
This is also probably a good time to dive in and double-check those scan profiles and triggers you have set up. If you are in the same situation we are going from a 10Gb network to a 2Gb VPN network, we don't have the luxury of pulling all the data as often as we want without getting in the way of our users and hogging resources for nice to have data. (Options > Scan Profiles)
T-Shoot
Finally, to wrap this thing up, I’ll share the quick tests you can use to verify your configurations and verify PDQ Deploy, and PDQ Inventory will work outside of attempting a scan or deployment. These tests should be run from the machine hosting PDQ Deploy and Inventory.
First, verify name lookups from a command / PowerShell prompt nslookup <target> in this example I’ll use Brook’s laptop:
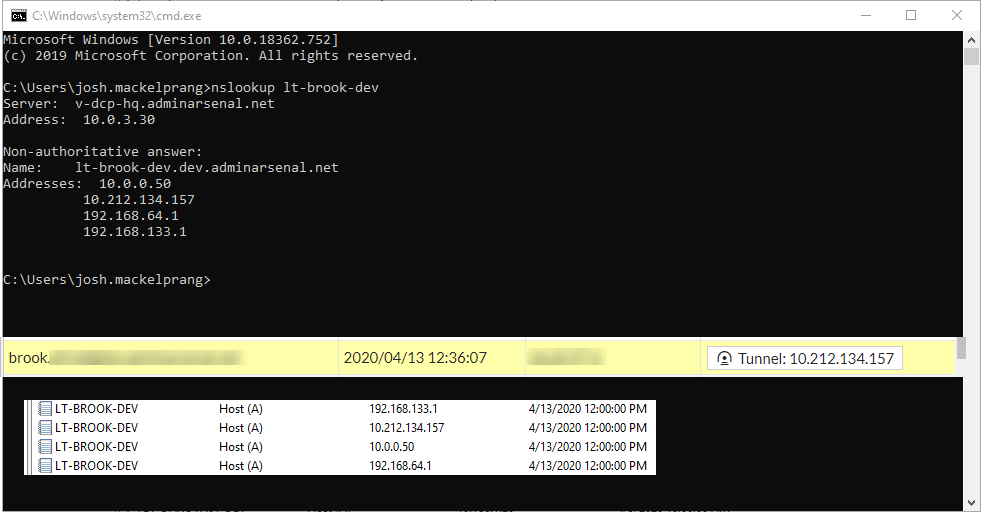
The yellow is the tunnel address issued by the firewall, so it looks like DNS is keeping up in this case.
Next, you can see that if we try to ping his machine to verify it’s online, we’ll get a false negative if we have ping before scanning/deploy enabled in PDQ Deploy and PDQ Inventory.
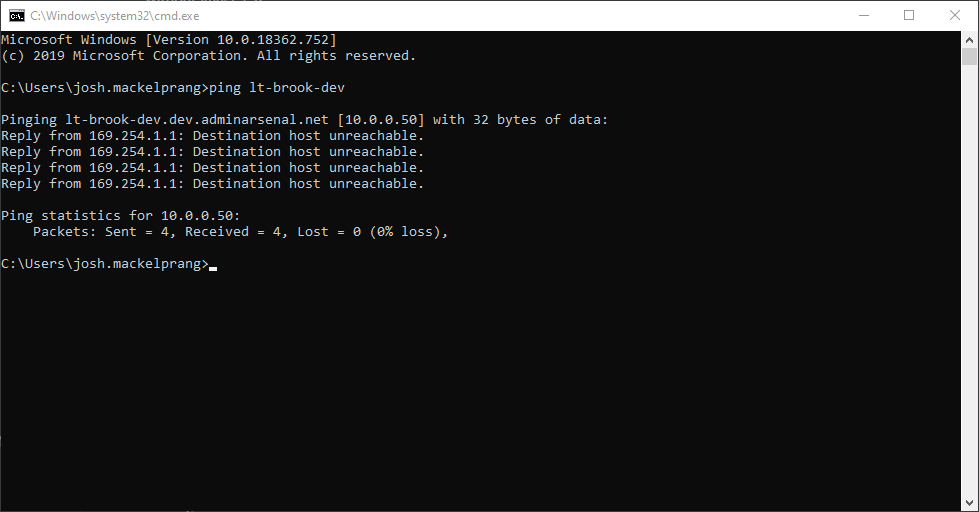
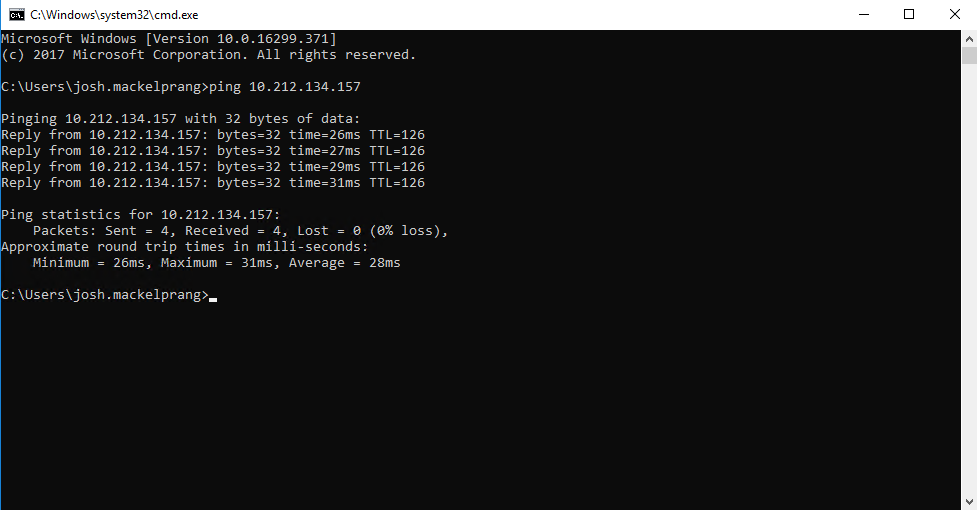
This is because the “10.0.0.5” address was returned first in the resolution query. If we ping the tunnel address we get live responses:
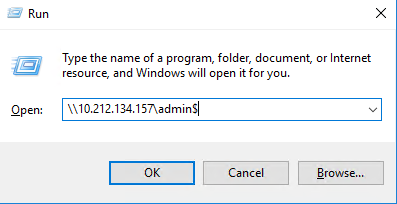
After that, let's make sure we can access the machine's administrative shares; this will test SMB connectivity. This can be quickly done from a run dialog box by entering \\<target IP address>\ADMIN$ this should open the file explorer at C:\Windows on the remote machine
All that’s left to do at this point is to scan his machine. If you can scan a machine with Inventory, you can deploy to the machine no problem.

Finally, that success we wanted! If ever there was a swear jar at PDQ, it would be overflowing by the time we nailed this down. Now wash your damn hands. While you're at it freshen up that day drink, you've been trying to hide in a coffee cup since your 9:30 AM meeting.
Loading...


